[vc_row][vc_column css=”.vc_custom_1700553037018{background-color: #efefef !important;}”][vc_column_text css=”.vc_custom_1701162815677{margin-top: 0px !important;margin-right: 10px !important;margin-bottom: 30px !important;margin-left: 10px !important;}”]
La notion d’Omnicanalité est désormais acquise. Les clients doivent pouvoir, quel que soit le canal ou le support, aller au bout de l’acte d’achat. Ainsi, la digitalisation de l’ensemble de l’information et la communication instantanée sont des éléments essentiels pour atteindre cet objectif. Cela entraîne des répercussions importantes sur l’IT et son organisation, ainsi que sur les méthodes de traitement des données.
[/vc_column_text][/vc_column][/vc_row][vc_row css=”.vc_custom_1701097008010{margin-top: 40px !important;}”][vc_column][vc_column_text]
Le traitement de la donnée
Tout d’abord pour ne pas froisser nos interlocuteurs de l’IT, il faut préciser ce que nous entendons par temps réel.
Le temps réel ça n’existe pas
Tout simplement parce que la Data, se transporte, se traite et s’intègre. Le temps nécessaire à ces opérations, peut varier de la milliseconde à la minute, voire à l’heure pour les opérations d’intégration.
Nous allons donc adopter la notion de « fil de l’eau » pour évoquer la gestion de la Data. Cette notion imagée est basée sur du traitement à « L’Event ». C’est-à-dire dire que les traitements vont se déclencher sur un événement identifié.
Par exemple :
- quand on demande à une application métier de générer et déposer un fichier de données, c’est un événement.
- on détecte qu’un utilisateur lance une requête, c’est un événement.
Le fil de l’eau, c’est l’immédiateté du traitement de la donnée lorsqu’elle est créée a contrario des traitements dits « par batch » qui collectent et mettent en attente un grand nombre de données pour les organiser, les transférer, les traiter et les intégrer. Ce qui implique une temporisation qui empêchera systématiquement l’immédiateté dont nous rêvons.
Aval et Amont de la chaine de valeur de la donnée : un focus sur les processus métiers
Le point de vente génère à la volée des tickets de vente. Ces ventes peuvent être générées par des terminaux de paiement, des outils mobiles, des bornes ou des caisses virtuelles. Ces ventes doivent être traitées et remontées vers le back-office, pour permettre la remontée du CA, des taxes, déclarer du stock vendu (et donc sortant), le calcul de marge, le suivi des versements banque, l’analyse des comportements d’achats des clients (encartés ou anonymes), la bonne application des prix de vente au consommateur et des campagnes promotionnelles…
Beaucoup d’enseignes traitent, encore aujourd’hui, ces informations en fin de journée (ou de période) après le lancement des clôtures. Désormais, chez les acteurs de la GSA et GSS (grandes surfaces alimentaires ou spécialisées), ce besoin a évolué depuis le développement du web et poussé par l’omnicanalité.
Aujourd’hui, les données de vente sont traitées au fil de l’eau et remontées vers les systèmes centraux (ERP, CLOUD, DATAHUB …). De plus, cette information est également partagée immédiatement avec tout l’écosystème des applications métiers.
Ces évolutions ont eu un impact direct sur l’ensemble de l’organisation IT. Il a fallu faire évoluer les applications, les flux et leur traitement. Concrètement, c’est toute l’architecture du système d’information qui a dû s’adapter.
Prenons le cas de la gestion des stocks disponibles :
L’événement « vente d’une pièce », que ce soit dans un point de vente, en drive ou sur un site e-commerce, doit être immédiatement partagé avec l’amont, le web et les autres points de vente de l’enseigne. Les opérations et les tâches qui découlent de cet événement permettent d’informer immédiatement les collaborateurs de l’entreprise ainsi que ses clients notamment sur les points suivants :
- la mise à jour du stock sur le point de vente pour permettre le déclenchement de réassorts automatique,
- le site e-commerce doit mettre à jour les stocks pour les clients qui utilisent le click & collect ou la e-reservation, afin de les orienter vers le bon point de vente (ou canal de vente),
- le Drive qui partage ses stocks avec la grande surface !
On comprend bien que tous les processus métiers sont impactés.
La supply, la logistique, le marketing, la relation client… tous vont devoir adapter et enrichir leurs processus pour travailler avec des données qui évolueront très vite au cours de la journée.
On aurait pu évoquer également :
- la Business Intelligence : tous les univers et leurs indicateurs de performance devront être modifiés,
- la communication au client : le lancement des campagnes de communication ciblée sera plus Time to Market et pertinent,
- le marketing : les résultats d’une campagne promotionnelle seront connus immédiatement,
- la logistique : le déclenchement des approvisionnements sera immédiat et permettra une plus grande agilité dans la planification des livraisons.
En résumé, le traitement de l’information « au fil de l’eau » signifie que l’information pertinente pour la prise de décision est disponible sans délai. Pour le client, comme pour l’enseigne.
[/vc_column_text][/vc_column][/vc_row][vc_row][vc_column][vc_column_text]
Comment mettre en place une architecture applicative adaptée au traitement de la donnée en “temps réel” pour l’IT ?
Nous comprenons que les systèmes de bases de données et l’architecture des flux traditionnels ne permettent plus de répondre aux exigences imposées par le Big Data ou des données de diffusion en continu. Le « temps réel » en comparaison du mode « batch » va englober tous les traitements de données qui nécessitent un temps de calculs court ou un besoin d’information fort.
Par exemple : mise à jour du référentiel, descentes des promotions, remonté du CA ou des stocks…
Ici, les résultats du traitement de données seront donc dits « chauds » pour le temps réel versus « froids » pour le traitement par « batch ». L’impact est structurel et nécessite la création d’une architecture dite Lambda.
L‘architecture « Lambda » est une superposition de couches : on conserve une couche « batch » (Lot), on y ajoute une couche « temps réel » (fil de l’eau), et une couche « services », soit :
- la couche « batch » (lot) traitera des flux de données plus volumineux pour lesquels on est obligé d’avoir des traitements plus long (ex : Initialisation du référentiel),
- la couche « temps réel » (Speed Layer) traitera les données au fil de l’eau. Moins volumineuse mais en flux constant et régulier (ex : Tickets de caisse),
- la couche « services » conserve, intègre, agrège et expose les données (ETL, ERP, DATAHUB …).
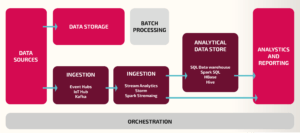 En synthèse, l’architecture « Lambda » consiste essentiellement à mettre en place au sein du même système d’analyse de données, deux processus :
En synthèse, l’architecture « Lambda » consiste essentiellement à mettre en place au sein du même système d’analyse de données, deux processus :
- un processus qui va permettre le traitement des données en mode batch
- un processus pour analyser les données en temps réel (au fil de l’eau)
Cette architecture est rendue possible grâce à la technologie KAFKA. Apache Kafka est une application open source de traitement des flux de données et de mise en file d’attente des messages, capable de traiter jusqu’à plusieurs millions de messages par seconde, en provenance de différents producteurs, et de les acheminer vers plusieurs consommateurs. Il existe d’autres solutions pour répondre aux besoins (par exemple, via une API, mais c’est une autre histoire).
[/vc_column_text][/vc_column][/vc_row][vc_row css=”.vc_custom_1701100087312{background-color: #ffffff !important;}”][vc_column css=”.vc_custom_1701100121202{background-color: #ffffff !important;}”][vc_column_text css=”.vc_custom_1701100095029{margin-top: 20px !important;margin-right: 10px !important;margin-bottom: 20px !important;margin-left: 10px !important;background-color: #ffffff !important;}”]
Vous l’avez compris, c’est toute l’architecture, et même l’organisation du SI qui est impacté.
Le nécessaire partage de l’information nous oblige à faire évoluer nos systèmes vers cette solution de traitement des flux de données. Parce qu’elle répond aux besoins du métier et aux enjeux à venir.
Chez Univers Retail, notre mission est de prendre du recul pour comprendre et appréhender les changements nécessaires afin de les mettre en œuvre. Cela implique de collaborer avec les équipes métier pour les accompagner dans la mise en œuvre des projets, des solutions et des processus. Il est également important de les soutenir dans les changements du quotidien afin que tous puissent réaliser les promesses du temps réel.
[/vc_column_text][/vc_column][/vc_row][vc_row css=”.vc_custom_1682523226414{padding-bottom: 15px !important;background-color: #efefef !important;}”][vc_column][vc_column_text]
Vous avez un projet concernant la Data ou vous souhaitez discuter avec l’un de nos experts ?
[/vc_column_text][rt_button_style title=”Contactez-nous” link=”url:https%3A%2F%2Fwww.universretail.com%2Fcontact%2F|title:Contact” animation=”fadeInUp”][/vc_column][/vc_row]